
Brave, Ceramic, and Web3's data problem
To be competitive, Web3 must realize the value of data

With the recent growth of tools like Ceramic, IPFS, and Arweave, an architecture for a more decentralized internet is slowly emerging where data is stored in personal data stores rather than corporate servers or centralized cloud services. Personal data stores mean that users will, for the first time, be able to fully own their data, control how their data is used, and command a larger share of their’s data value. With data from different applications stored together under a user’s control, lower friction data sharing between applications should also lead to far greater composability and a richer ecosystem of dapps than is possible currently.
Despite this promising vision, moving to a user-centric data ownership model is a significant change that won’t happen overnight. It’s worth exploring how things might play out, starting with where things stand now.
App-centric data storage means data silos

Today if a user is browsing a website, the data they generate gets stored in two primary locations - the browser and company-owned databases. If you sign up for Facebook and create an account, then data about your account and first post will go straight to Meta’s servers. If you then go and create an account for Gmail, then that gets stored separately in Google’s servers. This approach is known as the app-centric data storage model.
Since data is stored in separate silos by companies, there is little direct control in how the data gets used. It can be copied, used for unauthorized purposes, or resold without your knowledge or consent, although regulations like GDPR and CCPA help somewhat. It’s also difficult for users to share data between applications. If you’re a developer, you could get the user’s credentials and then do an API integration behind the scenes to fetch data (e.g. integrating Plaid to connect to Chase), but that isn’t a small amount of work.
“Data pods” provide composability for dapps using off-chain data
The user-centric data storage model has been under development by Tim Berners Lee, the inventor of the internet, since at least 2017. According to this vision, individuals should be able to choose where their data lives and who has access to it. Within Web3, this means storing data on a service like IPFS in association with the user that created it, rather than on a corporate server based on the application that created it1. Note that centralized cloud services like AWS or Google Cloud do not qualify as “personal data stores” because Amazon and Google still have unrestricted access to user data. In contrast, by using services like Ceramic in combination with decentralized storage, data can be encrypted and its access managed by users using cryptographic keys so that no one except the user can interact without permission.
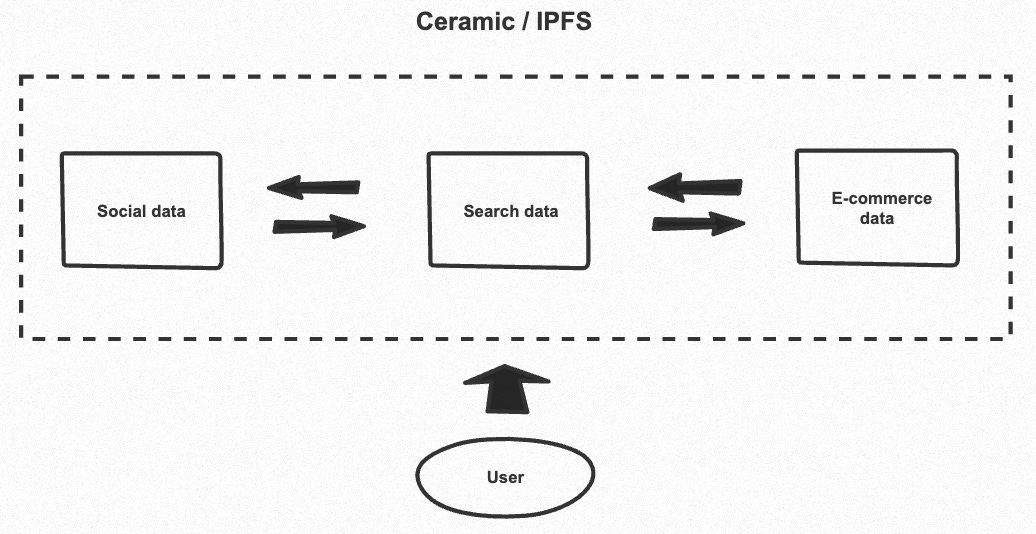
For an example of what’s possible using personal data stores, let’s say that you used Sign In With Ethereum (SIWE) to log into a decentralized social media app. Your interactions with that app then go into your personal data store. Later when you log into a decentralized marketplace, you share access to your social media follows stored in your “data pod”, and receive customized recommendations based on those. Using an accessible index contained in your “pod” of all sites you have created accounts for, the marketplace app might even discover your account on Adidas.com and offer you discounted sneakers.
With this setup, users can easily manage which data is be shared with whom. The same flow that users use today to grant access to their Google data, could be repurposed by users to grant access to their any or all of their dapp data. If users didn’t want to share but rather just wanted to delete all their data, this model would also give them complete control to make that decision.
On the other side, developers who want to allow users to either share data or access dapp data can do so without dealing with custom API integrations. Instead, a universal login service (like SIWE) and the “data pod” could be combined to form a re-usable pattern for granting access to data. It would be as if even the smallest startups in the world could implement their own Google login to share data externally, or use Google login to access any other company’s data.
The end result of this should be greater composability. Although data accessibility rarely affects composability for dapps using on-chain data, since blockchain data is transparent, it can be problem for dapps leveraging sensitive off-chain data, which must be carefully permissioned to protect user privacy. The usage of a universal login solution (e.g. SIWE) to grant access to compartments within this personal “data pod” solves this problem and allows dapps using off-chain data to interact more easily.
Beyond composability, to data ownership
Each year, the data of a typical US Google user is monetized to the tune of $256, while for a typical US-based Meta user this figure is $1122. Although tech companies currently generate revenue by collecting then monetizing large data sets of user-generated data, this approach changes if we adopt a user-centric rather than app-centric data storage model.
Today there are two main types of data used for advertising - first party data, which is collected by the website a user is visiting, and third party data, which is collected by a different party other than the user’s current site. First party data can be very detailed and valuable, but is difficult to obtain as it is must be provided directly by users3. An example of first party data would be account information submitted at signup, or a survey you fill out on an e-commerce site. Third party data on the otherhand, is more widely available, but much shallower. A third party cookie from Google can track your URLs as you navigate across sites, even while you are on non-Google sites, and share the data with Google. This data has breadth, but not depth since URLs don’t contain much additional detail on the user.
One core problem in the adtech industry is related to tracking people across browsers and devices. As the cookies relied upon heavily for tracking cannot follow people across browsers even on the same device, if users don’t login or submit their emails, it can be difficult to tell who they are. Fragmented data is less valuable. Assume you work at Nike - if you know John visited adidas.com earlier on Firefox desktop, but you don’t know that the person currently visiting a partner site on their iPhone is also John, then you’ve just missed the opportunity to show a sneaker ad. Since third party cookies are already banned on Firefox as well as Opera, and will be removed from Chrome by 2024, tracking users across devices is only going to get more difficult.
If third party data is becoming less reliable, first party data is a natural alternative to consider. Even assuming sites like the New York Times are willing to sell data on what stories their logged in users read and comment on, there’s no easy way to do this. Since there’s no technical framework, manual work is needed to make the data accessible to external parties and to accept payment for the data.
Web3 data will be more accessible and standardized
Just as the open, accessible, and discoverable nature of data stored in personal data stores increases composability, it also presents significant potential improvements for data monetization. The same “Sign in with X” pattern which can be used by developers to gain access to data for development purposes, can also be used by advertisers and users to exchange and monetize data.
Addressing today’s obvious industry problems, user-centric data storage would make it fairly easy to track users across devices, as long as they are logged in using decentralized identity solutions like Sign in With Ethereum. In the intermediate term, the improved technical framework and monetization potential provided by personal data stores would also allow far larger quantities of high-quality first party data to become available. All of the data stored by companies like Meta or Google on their servers, could theoretically potentially be made available within personal data stores, subject to privacy concerns, storage limits, and other technical considerations.
In the long term, however, the potential for improved open data standards could make life an order of magnitude easier for engineers, data scientists, and data engineers who today struggle with messy data. If large volumes of what are today opaque “proprietary” datasets are made openly accessible (albeit possibly requiring payment), it will be easier to converge on data standards, whether through direct coordination or people copying what others are doing. It’s not too hard to imagine standardized formats for storing e-commerce data, financial transaction data, credentials, etc. Having a user-centric data storage model wouldn’t just make things better for users, it could make life substantially easier for developers and advertisers as well.
Most importantly however, assuming that larger volumes of first party data become available and make advertisers better off, users could end up claiming a larger but still sustainable share of their data’s value. Companies like Brave have already started giving users a share of revenue from the ads they are seeing, but this can be taken further. If users are willing to opt-in to sharing higher quality data, more valuable data becomes available, and then users can take can take a cut of this (e.g. Brave Rewards) while everyone is better off. The key however is user choice. Many users undoubtedly value their privacy, but for users who prefer otherwise can choose capturing the value of their own data over privacy.
If Web3 is basically just more ads, but with users getting a larger share of the value, that’s certainly not a bad starting point. We can still do better, however, by considering smarter ways to capture the value of data.
Building a global data marketplace
Rather than subjecting users to today’s ads, we can opt to let users to sell their data directly. These data marketplaces exist today, but mostly involve third parties and data brokers selling data in gray markets without visibility or consent from users.
Future data marketplaces could be implemented in open source with privacy controls built-in. If data from users hosted primarily on personal data stores, you could envision a unified marketplace which contains access to data from most users on the internet. Users would be able to choose which data they could sell, as well as the minimum amounts they would accept for that data. Marketers could search for users meeting specific attributes, or users of specific dapps. Academic researchers could come with a budget and, in a few minutes, obtain a targeted dataset from their specific research projects.
Online marketplaces in theory aren’t difficult to build - they’ve been around for ages (think Craigslist). However there are a few unique problems that need to be solved for personal data marketplaces. The first is rather simple - once data is sold, it is out of the user’s control and can be infinitely copied. You could avoid this problem somewhat for data where recency is very important (e.g. which websites you’ve visited recently), but other types of data would almost certainly get resold. Privacy-preserving tech offers some solutions here which we’ll get into later.
Companies or apps with available data will also need some incentive to give up control of user data, and would be likely to ask for a percentage of data sales. This might seem out of place for user-owned data, but remember that A) their current share of data monetization revenue is 100%, which is greater than say 5% and B) without participation from data sources there would be nothing for users to monetize. If you’re a marketplace, you need both supply and demand. Companies would also ask for some degree of control over who the data gets sold to. Nike won’t want their most valuable user data being purchased for cheap by Adidas. Some won’t buy in at all, some will offer up some data while others will fully embrace open data exchange.
Lastly it could be tricky to figure out how to price data. The value of data depends on not exclusively on the piece of data you’re buying, but also how much data you already have to combine it with in order to train a model, and what you’re using the data for. Most people would have no idea how to price their data, so we’d need good recommendations for how much to sell data for. For more on the pricing of data, see the excellent resources in the footnotes from Ocean Protocol45.
Everyone hates ads, but no one wants to actually pay
Is it viable to get rid of ads entirely, and support Web3 solely through users selling data? This seems unlikely, since the purpose of buying data for many companies will be likely to serve ads. Besides, there is a fundamental reason that ads are so widespread.
Why do ads exist today? Surveys show that 75% of Americans find online ads intrusive6. Outside of Super Bowl ads, pretty much no one likes ads.
The simple answer is that quality content and services take money to produce. The New York Times has 5000 employees, and Google has teams of employees making improving the algorithms for their free Maps product, all largely free. On a website with the option to pay, it’s estimated that only 1-3% of users will opt to pay money7. Even for those willing to pay, the value of some content or websites (e.g. that short sports story you read the other day) might be worth such a small amount of money (e.g. $0.10) so as to be not worth the effort to make a micropayment. For these reasons, Web 2.0 has defaulted towards ads using to pay for free offers ranging from funny Buzzfeed stories to short Tiktok videos.
Web3 has come up with new monetization options, but none solve the key problems for the 95% of users who don’t want to pay. NFTs are definitely valuable tools for content creators or media companies, but these will only likely be purchased by highly engaged fans. They wouldn’t help with capturing the other 95% less engaged fans who don’t want to purchase. Micropayments are great, but probably will still fail for the same reasons as in Web 2.0, because the effort they involve will not be worth it for small transaction amounts (e.g. $0.10). Ads, by contrast are shown and generate income for sites by default, whether the user does clicks or not.
Everyone hates ads. But no one hates them enough to actually pay for things. If Web3 can’t find ways to realize value from data, it will have no realistic chance of competing.
Federated learning protects privacy
If ads are a necessary evil, how can we make them better in Web3? This brings us to our last discussion, privacy preserving ads.
Brave Browser is a pioneer in the crypto space known for its privacy-focused browser, which blocks most traditional ads, as well as its privacy-preserving advertising. As a browser, Brave has access to data like browsing history which might one day be stored in personal data pods. To replace the traditional ads which it blocks, Brave Browser shows opt-in ads to users as browser notifications. Users who view these opt-in ads then earn rewards for doing so. Interestingly, Brave also runs a “ad network” where advertisers can purchase ads targeted to users who show interest in specific topics, like “sports”, “shopping”, or “travel”.
Brave’s advertising is unique because it uses privacy-preserving machine learning to decide which ads to show. Brave utilizes a special technique called “federated learning” to train their advertising models to predict which ads users are most likely to click on. With federated learning, a “small piece” of a model is first trained on a user’s device using their own data, then this “small piece” is sent to a central server to be combined with other pieces to form a final model. In contrast to techniques used by companies like Google, where advertising models are often trained on large amounts of data housed centrally either on a server or cluster of servers, this technique ensures that no private data ever leaves the user’s device8. The idea is that if no private data ever leaves the user’s device, then their data is protected against being resold or exploited without their permission. There are still some privacy issues to work - for example, looking at a user’s piece of the model might tell you a bit about what their data looks like. Ultimately though as long as the final model is sufficiently predictive, this setup is still miles better than the status quo for privacy.
In a world where all user’s data is available on personal data pods, an enormous amount of data will be available to all parties (not just specific companies), and many more models, not just advertising models, can be trained on this data securely. Think models for healthcare, trained off of patients’ medical data, rather than models predicting people clicking on ads.
The state of technology
How far away are we from realizing this vision?
The decentralized storage layer is already in place. Immutable storage services like IPFS and Arweave have each been around for 7 and 5 years respectively, and are rapidly maturing. Note that these data stores must be immutable, since in a decentralized environment care must be taken that data isn’t manipulated. On top of these, tools like Ceramic or ThreadsDB from Textile add a “mutability” layer that makes it easier to modify data by implementing an append-only ledger on top of immutable storage910. Although each additional update in the ledger is immutable, the final result from parsing the combined updates is mutable, just as how Bitcoin account balances can change even though individual past transactions are immutable.
Privacy and permissioning features are areas which could still use further development. Ceramic seems to have only recently implemented a permissioning system, which may still need some time to mature and become fully robust11. For privacy-sensitive users, it could be useful to have an implementation of the data pod that works on user’s personal devices, rather than on third party decentralized storage nodes. For data stores implemented on personal devices like phones and computers, data could likely be taken online or offline as needed and there would be less concern about if storage nodes had actually deleted or had otherwise somehow replicated your data. Additional layers to help with capturing the value of data largely seem undeveloped. Protocols focused on simple data exchange and monetization could be a good starting point. Beyond that, protocols to create decentralized data marketplaces or to enable federated learning on personal data stores.
One last missing piece to consider alongside technology is regulation. Though companies may adopt personal data stores if users demand it, they cannot be compelled to not also store extra copies of the data elsewhere. Future laws similar to GDPR (General Data Protection Regulation), an EU law on data privacy, could both enforce better behavior and accelerate corporate adoption of personal data stores as an easier method to comply with privacy regulations. These regulations, like personal data stores, can be powerful tools to help secure data privacy (and data ownership) as fundamental rights for users.